Noindex blijft een belangrijk fenomeen binnen SEO. Noindex links en noindex pagina’s spelen nog steeds een grote rol binnen linkbuilding, het bouwen van autoriteit en SEO in het algemeen. Wat zijn noindex links? Hoe zet ik noindex links in voor SEO? En welke noindex checkers zijn er? Je leest het hieronder!

Geschreven door:
Ali Demir
Wat is een noindex link?
Noindex is een HTML-attribuut, waarmee je webcrawlers aangeeft dat de pagina in kwestie niet geïndexeerd mag worden in zoekmachines. Weliswaar heeft de pagina een functie, maar deze mag niet geïndexeerd worden. Denk hierbij bijvoorbeeld aan een inlogpagina op jouw website, of een specifiek PDF-bestand dat alleen voor bezoekers bestemd is.
Hoe zet ik noindex link in voor SEO?
Er is geen actieve manier om noindex links voor SEO in te zetten. Je geeft door middel van dit HTML-attribuut simpelweg aan dat je niet wilt dat de zoekmachine de pagina indexeert, in tegenstelling tot bijvoorbeeld de dofollow of doindex. Dit kun je onder andere doen via jouw robots.txt-bestand. Ook op WordPress kun je per pagina aangeven of je deze wilt laten indexeren of niet. Eerst download je de plug-in Yoast of Rank Math. Hierna ga je naar ‘geavanceerd’, waarna je bij ‘sta zoekmachines toe om deze Pagina te tonen in zoekresultaten?’ op nee drukt.
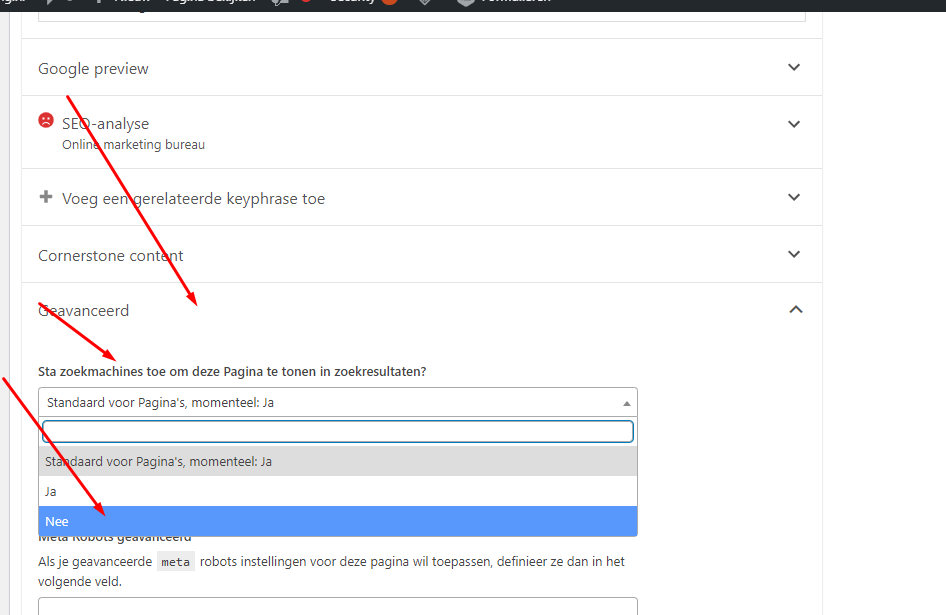
Via bovengenoemde manier zet je een pagina op noindex door middel van de meta robots. Toch zijn er nog 2 andere manieren om een pagina op noindex te zetten:
- Via disallow in robots.txt
- Via een canonical naar een andere URL
Noindex checkers
Wil je controleren of een pagina op noindex staat of niet, kun je allereerst via de broncode gaan kijken. Je drukt op een willekeurige pagina op een website op jouw rechter muisknop, waarna je op ‘inspecteren’ drukt. Vervolgens doe je CTRL + F en type je hier ‘noindex’ in. Op deze manier kun je vanzelf achterhalen of een pagina op noindex staat of niet. Ook zijn er natuurlijk diverse noindex checkers. We hebben er enkele voor je op een rij gezet:
- https://adresults.nl/tools/indexatie-checker/
- https://www.seoreviewtools.com/bulk-meta-robots-checker/
- https://seositecheckup.com/tools/noindex-tag-test

Noindex-tag of robots.txt?
Er is nog een andere manier om aan een zoekmachine door te geven om een pagina te negeren. Dat kan via de robots.txt. Daarin kan je de disallow-rule per pagina opnemen. Echter moet er wel bij gezegd worden dat het een vergelijkbare, maar toch andere functie vervult dan bij noindex. Met de noindex-tag geef je te kennen dat je de pagina niet wilt laten indexeren. Bij een disallow-rule in het robots.txt bestand geef je aan dat je de pagina niet wilt laten crawlen. Het verschil tussen noindex en robots.txt zit dus in het feit dat in het eerste geval Google jouw pagina wel crawlt en beoordeelt, maar simpelweg niet meeneemt in de indexering. In het tweede geval geef je aan dat Google de pagina in het geheel niet door bots laat uitlezen, maar zegt niets over toestemming om het te laten indexeren. Het probleem dat kan ontstaan als je een noindex-pagina een disallow-rule in de robots.txt meegeeft kan erg verwarrend zijn. Omdat de pagina is uitgesloten om te laten crawlen kunnen de bots niet lezen dat de content op noindex staat waardoor er een kans bestaat dat Google via een omweg toch besluit om jouw pagina te indexeren. Hoe kan dat zal je denken? Een mogelijkheid is dat de zoekmachine via een backlink op de verboden pagina terechtkomt en zodoende toch een bepaalde autoriteit aan die pagina toekent zonder dat Google naar de inhoud ervan kijkt. Als er dan ook nog bezoekers op de landingspagina belanden zal Google de pagina zeker erkennen en opnemen in de zoekresultaten.


